Chipa’s text-to-vector service: spacy.io with gRPC API.
Multistage docker build.
Acceptance testing on gitlab ci pipelines.
Going open-source.
- Сервис text-to-vector
- gRPC сервер для spacy NLP
- Poetry, сборка в Docker образ
- Acceptance testing on gitlab CI
- Исходный код
Сервис text-to-vector
Несколько слов про word embeddings
Сервис chipa позволяет создать FAQ бота из таблицы вопросов и ответов.
Когда пользователь задает вопрос, бот ищет наиболее похожий по смыслу вопрос из таблицы FAQ.
“Смысл” текста для бота представлен в виде вектора.
Вектор получается из текста при помощи Word Embeddings (NLP модели). Word embedding трансформирует текст в векторное представление так, что векторы 2-х похожих по смыслу текстов будут рядом.
Лучше про Word embeddings рассказано в этой лекции » курса Яндекс по NLP.
Выбор библиотеки NLP: spacy.io
Существуют разные NLP библиотеки для перевода текста в вектор.
До Chipa, я экспериментировал с Deep Pavlov в проекте ivoice. У DeepPavlov есть готовая реализация FAQ бота с использованием fasttext (пост про DeepPavlov autofaq »).
Для Chipa я выбрал библиотеку spacy.io:
- Множество готовых моделей для разных языков, с разным требованиям к ресурсам (чем точнее модель, тем требовательнее).
- Удобное и простое API для трансформации текста в вектор.
Требуемый от text-to-vector функционал опробован в jupyter-notebook »:
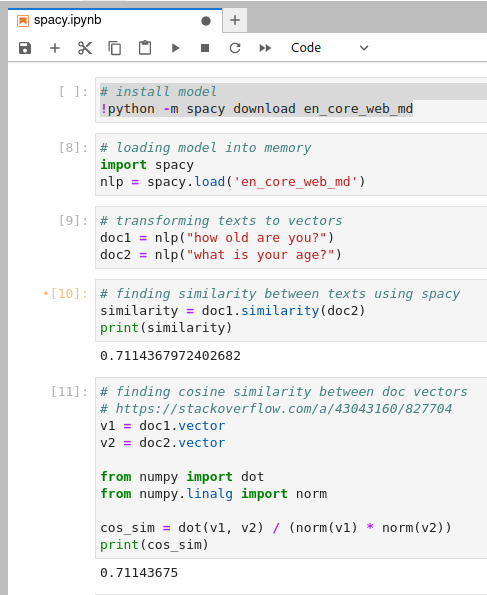
Ноутбук демонстрирует как для 2-х похожих текстов модель генерирует 2 близких вектора (cosine similarity для одинаковых фраз равен 1; чем ближе по смыслу тексты, тем ближе к 1 cosine similarity).
Векторы несвязанных текстов находятся далеко:
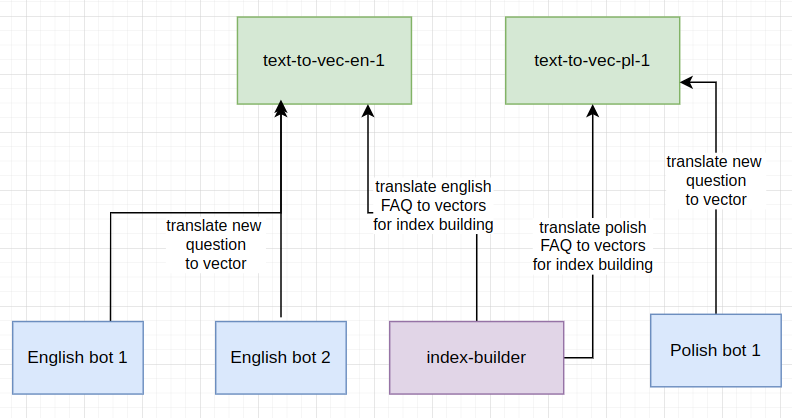
Проектирование text-to-vector
Text-to-vector участвует в 2-х процессах:
- Перевод вопросов из FAQ CSV в векторы при построении индекса, для дальнейшего поиска похожих вопросов.
- Перевод нового вопроса от пользователя в вектор.
Text-to-vector проектировался исходя из ограничений:
- Перед началом использования модель spacy должны быть загружена в память:
nlp = spacy.load(занимает несколько секунд) => модель необходимо загрузить до начала использования (serverless решение не получается) - Модель NLP для 1 языка занимает несколько сотен мегабайт => 1 загруженная модель должна делиться на множество задач трансляции текста в вектор на одном языке.
- Chipa является SaaS-решением: параллельно может работать множество ботов на разных языках, нет потолка возможной нагрузки (scalable)
- SaaS => обеспечить максимальную скорость ответа бота (основная ценность продукта)
- Cost effective SaaS => требуется обеспечить минимальные требования системы к ресурсам (уменьшить стоимость работы системы)
- Scalable => обсепечить возможность масштабировать систему горизонтально.
Ограничения продиктовали следующую архитектуру:
- Для каждой NLP модели запускается свой сервер (в случае масштабирования несколько)
- При запуске, spacy NLP модель загружается в память, что позволяет после запуска транслировать текст в вектор без задержки на загрузку, практически моментально.
- 1 сервис text-to-vector обслуживает все задачи трансляции текста в вектор на 1 языке (задачи связанные с построением индекса и новые вопросы из чатов с ботами).
- Система горизонтально масштабируется запуском дополнительных text-to-vector сервисов.
gRPC сервер для spacy NLP
В spacy.io из коробки доступен HTTP сервер на fastapi.
В chipa межсервисное взаимодействие реализовано на gRPC.
Причины данного выбора заслуживают отдельной статьи, и выгода от данного выбора, против использования готового сервера от spacy требует отдельной проверки.
Если бы я делал прототип, я бы нераздумывая взял готовый сервер spacy. Однако Chipa это пет-проект: возможность удовлетворить потребность в перфекционазме и поэкспериментировать.
Рассуждения о выборе между http и grpc можно послушать в этой лекции »
Реализация сервиса с использованием gRPC тривиальна:
Описание протокола в proto:
syntax = "proto3";
// Accepts text and transforms it to vector using spacy.io nlp
service TextToVector {
rpc Transform(Text) returns (Vector);
}
// Text to transform to vector
message Text {
string text = 1;
}
// Vector in spacy NLP model space
message Vector {
repeated double vector = 1;
}
Реализация сервера на python (source »):
class TextToVector(text_to_vector_pb2_grpc.TextToVectorServicer):
async def Transform(self, request: text_to_vector_pb2.Text, context):
logging.debug(f'Transforming: {request.text}')
vector = nlp(request.text).vector
return text_to_vector_pb2.Vector(vector=vector)
async def serve() -> None:
server = grpc.aio.server()
text_to_vector_pb2_grpc.add_TextToVectorServicer_to_server(TextToVector(), server)
listen_addr = f'[::]:{settings.port}'
server.add_insecure_port(listen_addr)
logging.info("Starting server on %s", listen_addr)
await server.start()
await server.wait_for_termination()
if __name__ == '__main__':
logging.basicConfig(level=logging.INFO)
settings = Settings()
start_time = time.time()
nlp = spacy.load(settings.nlp_model)
logging.info("nlp initialized in %s sec" % (time.time() - start_time))
asyncio.run(serve())
Poetry, сборка в Docker образ
Для packaging и dependency management system в python-сервисах Chipa используется Poetry.
Чтобы не тащить сборщик в production образ, сборка реализована как multistage build.
Stage 1: это временная фаза, в рамках которой устанавливается poetry (который мы не хотим в prod образе), который занимается подготовкой зависимостей requirements.txt.
FROM python:3.10-slim AS requirements
...
# install poetry
RUN apt-get update \
&& apt-get install -y --no-install-recommends curl \
&& curl -sSL https://install.python-poetry.org | python3 -
WORKDIR /src
COPY pyproject.toml ./
RUN poetry export -f requirements.txt --no-ansi --without dev --without-hashes -o /src/requirements.txt
Stage 2: Данный stage запускается с чистого образа python:3.10-slim и в него копируются requirements.txt, полученные на stage 1. Poetry на данном этапе уже не устанавливается!
FROM python:3.10-slim
WORKDIR /app
# Install requirements
COPY --from=requirements /src/requirements.txt .
RUN pip install --upgrade pip
RUN pip install --no-cache-dir --user -r requirements.txt
COPY text_to_vector_pb2.py ./text_to_vector_pb2.py
COPY text_to_vector_pb2_grpc.py ./text_to_vector_pb2_grpc.py
pip устанавливает requirements из requirements.txt - готов базовый образ (source для stage1,stage2 »)
Финальный образ для языка содержит модель spacy nlp (source »)
FROM registry.gitlab.com/archertech-chipa/spacy-grpc-text-to-vector/base
# models: https://spacy.io/usage/models
ARG NLP_MODEL
ENV NLP_MODEL=$NLP_MODEL
RUN echo "Downloading nlp model=$NLP_MODEL"
RUN python -m spacy download $NLP_MODEL
COPY service.py ./service.py
EXPOSE 50051
CMD [ "python", "service.py" ]
Acceptance testing on gitlab CI
Одной из мантр проекта является максимальная автоматизация (я его делаю один по выходным) и уверенность что все работает без меня (хочу сделать и забыть): человеческий QA в проекте непозволителен => требуются автотесты.
Критерий примеки text-to-vector сервиса:
- Text-to-vector запущен в виде docker контейнера для каждого доступного языка (на данный момент я включил русский, английский и польский).
- При трансляции 2-х похожих текстов, клиент получит 2 близких (cosine similarity) вектора.
Данный acceptance test полностью автоматизирован с использованием gitlab ci.
Tester script
Написан тестовый клиент, который транслирует 2 текста в векторы с использованием сервиса, и вычисляет cosine similarity полученных векторов (source »):
async def run(dimension: int, min_cos_sim: float, text1: str, text2: str) -> None:
async with grpc.aio.insecure_channel(settings.text_to_vector_service) as channel:
stub = text_to_vector_pb2_grpc.TextToVectorStub(channel)
print(f"Transforming text1: {text1}")
vec1: text_to_vector_pb2.Vector = await stub.Transform(text_to_vector_pb2.Text(text=text1))
print(f"Transforming text2: {text2}")
vec2: text_to_vector_pb2.Vector = await stub.Transform(text_to_vector_pb2.Text(text=text2))
assert len(vec1.vector) == dimension
assert len(vec2.vector) == dimension
print(f"Correct vector dimension = {dimension}")
# https://stackoverflow.com/a/1401828/827704
v1 = np.array(vec1.vector)
v2 = np.array(vec2.vector)
cos_sim = dot(v1, v2) / (norm(v1) * norm(v2))
print(f"cos_sim = {cos_sim}")
assert cos_sim >= min_cos_sim
print(f"Cosine similarity >= minimum threshold {min_cos_sim}")
Тестер проверяет:
- Сервер отвечает по gprc
- Векторы ожидаемой размерности
- Векторы достаточно близки
Ожидаемая близость текстов на разных языках получена в jupyter ноутбуке.
Gitlab CI
Gitlab CI позволяет сделать следующее:
- В рамках pipeline job запустить сервисы docker для тестового окружения (в данном тесте будет всего один, но можно запускать несколько, и они могут общаться между собой)
- Обратиться к данному образу из скрипта job
Acceptance test для английского образа, например, выглядит так source »:
test-image-en:
image: $CI_REGISTRY_IMAGE/base:latest
stage: acceptance
variables:
LANG: en
services:
# сервис на базе собранного ранее docker-образа, его тестируем
- name: $CI_REGISTRY_IMAGE/$LANG:latest
alias: text-to-vec-en
script:
- |
# скрипт вызывает API сервиса
GRPC_DNS_RESOLVER=native TEXT_TO_VECTOR_SERVICE=text-to-vec-$LANG:50051 \
python tester-client.py dim=300 min_similarity=0.71 "how old are you?" \
"what is your age?"
- В разделе services запускается образ text-to-vec с английской моделью, собранный ранее в рамках данного pipeline. Alias = text-to-vec-en делает сервис доступным по домену text-to-vec-en.
- В разделе script запускается tester, который проводит тест, используя запущенный сервис для трансформации текста в вектор (настройка EXT_TO_VECTOR_SERVICE=text-to-vec-$LANG:50051).
Теперь после каждого коммита, я могу быть уверенным, что всё работает как ожидается, без ручных проверок:
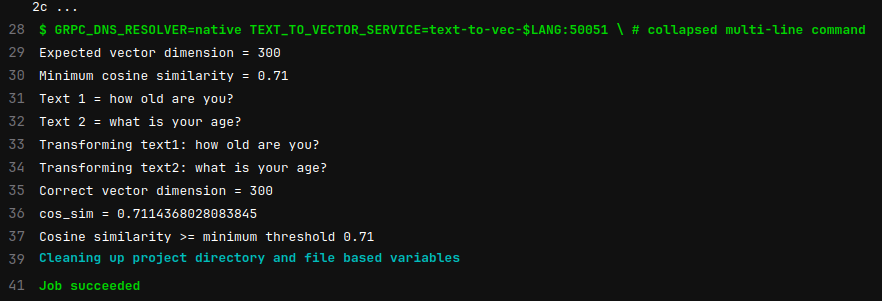
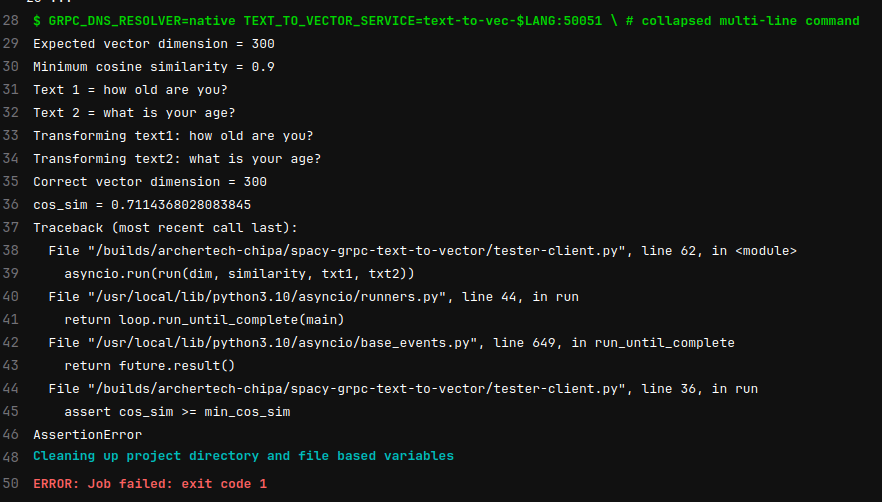
Если же что-то сломается, то pipeline не пройдет после коммита. Для примера, я увеличил ожидаемую близость векторов до 0.9 в английском тесте.
test-image-en:
image: $CI_REGISTRY_IMAGE/base:latest
stage: acceptance
variables:
LANG: en
services:
- name: $CI_REGISTRY_IMAGE/$LANG:latest
alias: text-to-vec-en
script:
- |
GRPC_DNS_RESOLVER=native TEXT_TO_VECTOR_SERVICE=text-to-vec-$LANG:50051 \
python tester-client.py dim=300 min_similarity=0.90 "how old are you?" \
"what is your age?"
Pipeline завершился ошибкой:
Исходный код
Сервис text-to-vector полностью доступен на gitlab: https://gitlab.com/archertech-chipa/spacy-grpc-text-to-vector