Пост про историю создания и архитектуру платформы ivoice.tech.
MVP
Всё началось в 2017 году с идеи Андрея Заворина: автоматизировать прием заказов такси и уточнения статуса заказа голосовым роботом. Диспетчерская такси работала на базе Яндекс такси и не имела API (взаимодействовать можно было только через веб приложение).

Требовалось поменять оператора на робота, и я разработал MVP, который выглядел так:
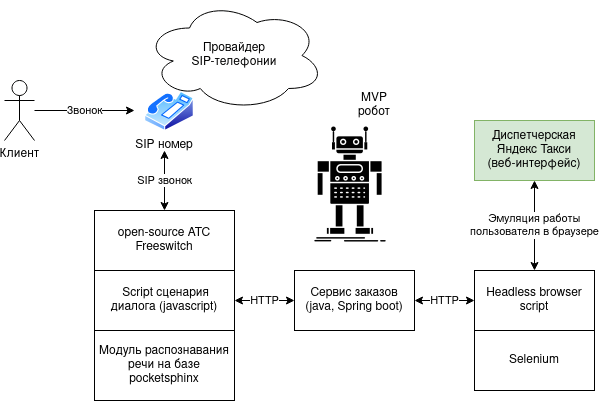
В процессе создания MVP надо было решить 3 задачи:
Задача 1. Принять звонок человека для обработки роботом.
Решается тривиально на базе open-source АТС. Изначально выбрал Asterisk, как более популярную АТС, но затем поменял на Freeswitch, т.к. мне он показался удобнее для программирования и имел в комплекте библиотеку для распознавания русской речи.
Задача 2. Разработать сценарий диалога с распознаванием речи.
Freeswitch позволяет писать диалоговые сценарии на нескольких языках (Javascript, Lua, Java).
Также у Freeswitch есть встроенный модуль pocketsphinx с русской моделью для распознавания речи.
Для MVP был написан скрипт приема заказа и уточнения статуса с реакцией робота на фразы человека (на Javascript).
Распознавание телефонной русской речи на pocketsphinx, работало… не очень хорошо :) Но если говорить в тишине и произносить фразы идеально, то pocketspinx распознавал корректно (сойдет для MVP).
Задача 3. Интеграция с веб-приложением диспетчера.
Последний челлендж заключался в отсутствии API в приложении диспетчера. Для MVP был разработан скрипт эмуляции действий человека в веб-приложении на базе headless browser engine и selenium.
Робот логинился в личном кабинете, кликал по кнопкам и т.п. Масштабировать такое сложно, но MVP заработал - робот принимал заказы по телефону и размещал их в приложении диспетчера, а также мог прочитать статус заказа и озвучить его по телефону.
Полный код MVP доступен здесь »
Со времени MVP очень многое поменялось, но каркас платформы был заложен.
Распознавание речи, twilio
Для запуска в production надо было разобраться с распознаванием, pocketsphinx не подходил.
Очевидным выбором было использовать вендоров распознавания (google, или яндекс speech).
Кстати, а почему не использовали Алису? Алисы тогда еще не было, мы начали чуть раньше.
У Freeswitch есть интеграция с распознаванием google через mod_unimrcp, но решение платное (50$/канал на тот момент).
Тогда я попробовал twilio - у twilio была интеграция с google speech, и можно было писать логику сценария, которая обрабатывалась в twilio. Решение выглядело так:
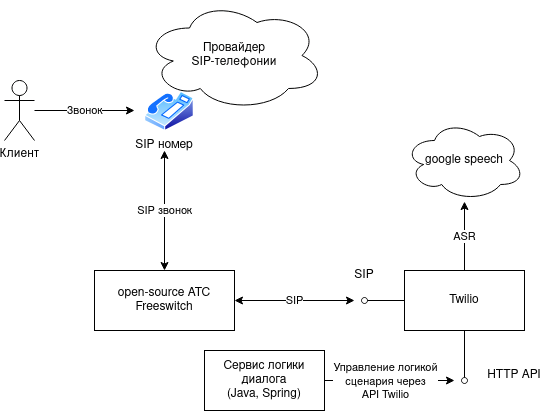
К сожалению у twilio было 2 минуса:
- Разгвор получался очень медленным
twilio умел определять конец фразы человека только через паузу молчания: т.е., если человек молчит 2-3 секунды, значит ввод произведен, и робот может отвечать. Также twilio добавлял свои задержки, в итоге ждать ответа робота можно было более 5 секунд.
В будущем в ivoice мы сделали гораздо более динамичный диалог, т.к. анализировали текст по ходу распознавания, используя streaming api.
- Дорого.
Нам нужно было только распознавание, и не нужен был twilio. Вопрос был в том, как интегрировать канал телефонного диалога freeswitch с вендором распознавания.
Ключевая точка в истории разработки платформы, первый production вариант
Я попытался разобраться со следующими вариантами интеграции freeswitch с вендором распознавания:
- Написать свой модуль uni_mrcp (это был бы самый правильный вариант при разработке сценариев скриптами freeswitch) - разработка на C.
- Написать модуль freeswitch, который отправлял бы канал голоса человека в распознавалку - разработка на C и C++.
К сожалению, у меня было 3 ограничения:
- Все должно работать вчера.
- Я тогда недостаточно хорошо умел разрабатывать на C и C++.
- Я был единственным программистом, и нанять C разработчиков было не на что.
Пытаясь в панике разработать интеграцию на C, я посматривал что есть в open source, и нашел Restcomm Connect, разработанный на любимой Java.
Restcomm Connect это полноценная АТС, у которой есть 2 качества:
- Плохое: функции АТС связанные с телефонией, она решает хуже чем зрелые технологии, такие Freeswitch или Asterisk. Также она гораздо более требовательная к ресурсам.
- Хорошее: использует для работы с голосом restcomm mediaserver, который как раз позволяет управлять звуком диалога простыми драйверами на Java.
В итоге удалось быстро сделать гибридное решение:
- Задачи телефонии решались на Freeswitch. Freeswitch переводил диалог на робота через SIP bridge.
- Робот был построен из компонентов Restcomm (mediaserver, sip-servlet, mgcp-control)
Мы убрали ненужные возможности АТС из этих компонентов, и разработали SDK для написания голосовых сценариев.
Решение выглядело так:
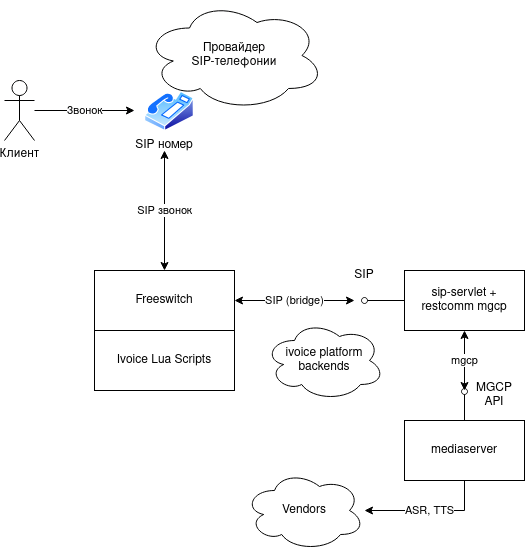
Это стало первым production вариантом ядра платформы ivoice (процессора голосовых диалогов), который в дальнейшем развивался в плане стабильности, новых возможностей и оптимизации.
Будущее, vert.x и open source
У решения на базе компонентов restcomm есть несколько серьезных минусов:
- sip-servlets - это тяжелые сервисы, которые запускаются на application сервере (wildfly)
- имеют слишком много ненужного нам функционала (см. спецификацию JSR 359)
- тяжелый для понимания и заброшенный legacy код на базе akka actors, на который завязаны все компоненты Restcomm
Всё что нужно от sip-servlet - это принять звонок от freeswitch и управлять медиасервером (командовать медиасерверу распознавать речь и произносить речь), см. описание call agent в спецификации mgcp ».
Сейчас в ivoice ведется разработка собственных компонентов, которые позволят:
- на порядки снизить потребляемые ресурсы диалога с роботом
- упростить разработку голосовых сценариев
- улучшить жизнь программистов!
Замена sip-servlets разрабатывается на базе vert.x, мы назвали ее robot-sip-server.
Система запускается за доли секунды и готова принимать звонки от freeswitch и обрабатывать голосовые сценарии.
Ivoice robot-sip-server доступен в open source.